Nowadays, whenever we hear about Big Data, there is always a mention about Apache Spark. Being a keen learner there are plenty of questions that come to our mind. Some of the most frequent questions are jotted down:-
- Why is Spark trending nowadays when we have Hadoop?
- Why is Hadoop being replaced by Spark?
- What should I do to learn Spark?
- Where to start?
We can find many answers once we google the right thing. Some of the suggestions are:-
- Start learning at least one of the three languages: Scala, Python or Java.
- Increase your awareness to the concept of distributed computing.
- Start reading Apache Spark Documentation.
Once we are done with this, there is only one thing left to do which is by far the most important thing, i.e., how to gain hands-on experience of developing a spark application? Because thinking about spark, we start thinking about huge clusters. This demotivates our aspiration to master the most trending technology in Big Data.
I here come up with a solution which will help you to run spark on local, i.e., on your own Eclipse-IDE. We can develop Spark application in any of three languages: Scala, Python, and Java. As Scala is the first choice with Spark in the production environment and so is my experience with Spark-Scala, I am going to share steps to set up Spark-Scala application on Eclipse.
STEPS :-
1. Download Eclipse: - You can download Eclipse for Java or Scala. If your PC is a 32-bit system then download eclipse for 32 bit and if it is a 64-bit system then download it for 64 bit.
Link - http://www.eclipse.org/downloads/
2. Go to Eclipse folder and open eclipse application.

3. Set WorkSpace.
4. If you have downloaded a Scala IDE, then it is fine. If you have downloaded a Java IDE install scala from the marketplace.


5. Create a Maven Project with group id(package) - com.demo and artifact id(project) - MyFirstProject



6. Go to ,m2 folder, it is by default created to your user. For me it is : C:\Users\Mohit\.m2 . Create a settings.xml file in this folder and write the following XML =>
-----------------------------------------------------------------------------------
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<proxies>
<proxy>
<id>p1</id>
<active>true</active>
<protocol>http</protocol>
<host>your_host</host>
<port>your_port</port>
<nonProxyHosts>10.*</nonProxyHosts>
</proxy>
</proxies>
</settings>
-----------------------------------------------------------------------------------
7. Open pom.xml of your project.

Replace the content with this:-
----------------------------------------------------------------------------------
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.demo</groupId>
<artifactId>MyFirstProject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>
----------------------------------------------------------------------------------
8. If you are using Java Eclipse IDE, then add scala nature.
Right click on project -> Configure -> Add Scala Nature

9. Change scala version to 2.10.
Right click on project -> Properties -> Scala Compiler -> Tick on use project settings -> Select Latest 2.10 bundle(dynamic) -> Click OK -> Click OK on Compiler settings changed pop up.


10. Right Click on Project -> Run As Maven install


Once maven is successfully installed, BUILD SUCCESS is printed in the console.
11. Create a HADOOP_HOME folder in your Workspace. Create bin folder inside HADOOP_HOME and copy the following files there.
For 32 bit system -> https://drive.google.com/open?id=0B0w0JKH3mMG-ZmQ1dlFaNC1RM2s
For64 bit system -> https://drive.google.com/open?id=0B0w0JKH3mMG-cDBkUk5vSk03Vnc
Unzip the file -> Copy the file content to the path => C:\Users\Mohit\workspace\HADOOP_HOME\bin folder(your workspace path in your case)
12. In Eclipse add HADOOP_HOME path in the following location =>
Window -> preferences -> java -> build path ->classpath variable -> new -> name: hadoop.home.dir -> path : C:\Users\Mohit\workspace\HADOOP_HOME



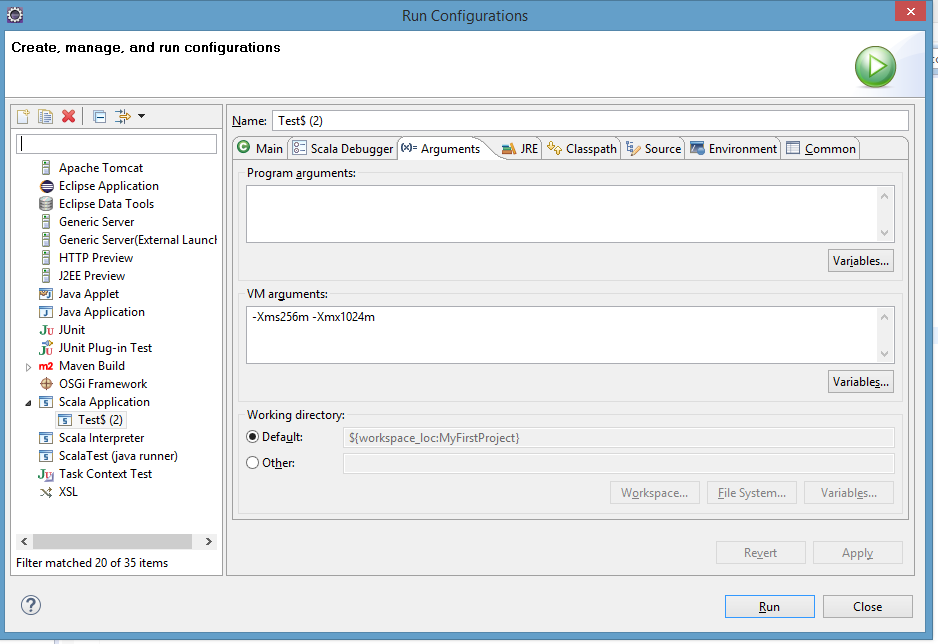
13. Add VM Arguments in Run Configurations as =>
Run -> Run configurations -> Scala application -> Arguments -> VM arguments -> -Xms256m -Xmx1024m

Congratulations!!! You have successfully set up spark on your ECLIPSE IDE. Let us run a small spark program to check whether we are able to run Spark.
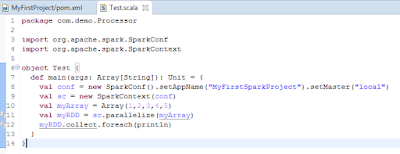
Sample Spark Program =>



----------------------------------------------------------------------------------------
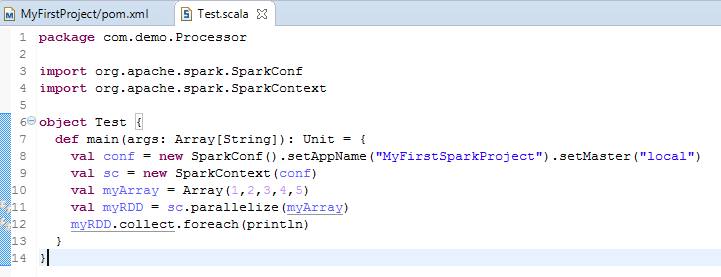
Code =>
package com.demo.Processor
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MyFirstSparkProject").setMaster("local")
val sc = new SparkContext(conf)
val myArray = Array(1,2,3,4,5)
val myRDD = sc.parallelize(myArray)
myRDD.collect.foreach(println)
}
}
----------------------------------------------------------------------------------------
Right Click on Test.scala -> Run AS -> Scala Application


It's working!!! Have fun with Spark :)
Thank you for patiently reading my blog. Hope you have successfully configured Spark on your Eclipse IDE.
Stay connected for future posts!!
Link - http://www.eclipse.org/downloads/
2. Go to Eclipse folder and open eclipse application.

3. Set WorkSpace.
4. If you have downloaded a Scala IDE, then it is fine. If you have downloaded a Java IDE install scala from the marketplace.


5. Create a Maven Project with group id(package) - com.demo and artifact id(project) - MyFirstProject



-----------------------------------------------------------------------------------
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<proxies>
<proxy>
<id>p1</id>
<active>true</active>
<protocol>http</protocol>
<host>your_host</host>
<port>your_port</port>
<nonProxyHosts>10.*</nonProxyHosts>
</proxy>
</proxies>
</settings>
-----------------------------------------------------------------------------------
7. Open pom.xml of your project.

Replace the content with this:-
----------------------------------------------------------------------------------
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.demo</groupId>
<artifactId>MyFirstProject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>
----------------------------------------------------------------------------------
8. If you are using Java Eclipse IDE, then add scala nature.
Right click on project -> Configure -> Add Scala Nature

9. Change scala version to 2.10.
Right click on project -> Properties -> Scala Compiler -> Tick on use project settings -> Select Latest 2.10 bundle(dynamic) -> Click OK -> Click OK on Compiler settings changed pop up.


10. Right Click on Project -> Run As Maven install


Once maven is successfully installed, BUILD SUCCESS is printed in the console.
11. Create a HADOOP_HOME folder in your Workspace. Create bin folder inside HADOOP_HOME and copy the following files there.
For 32 bit system -> https://drive.google.com/open?id=0B0w0JKH3mMG-ZmQ1dlFaNC1RM2s
For64 bit system -> https://drive.google.com/open?id=0B0w0JKH3mMG-cDBkUk5vSk03Vnc
Unzip the file -> Copy the file content to the path => C:\Users\Mohit\workspace\HADOOP_HOME\bin folder(your workspace path in your case)
12. In Eclipse add HADOOP_HOME path in the following location =>
Window -> preferences -> java -> build path ->classpath variable -> new -> name: hadoop.home.dir -> path : C:\Users\Mohit\workspace\HADOOP_HOME



13. Add VM Arguments in Run Configurations as =>
Run -> Run configurations -> Scala application -> Arguments -> VM arguments -> -Xms256m -Xmx1024m

Congratulations!!! You have successfully set up spark on your ECLIPSE IDE. Let us run a small spark program to check whether we are able to run Spark.
Sample Spark Program =>



----------------------------------------------------------------------------------------
Code =>
package com.demo.Processor
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MyFirstSparkProject").setMaster("local")
val sc = new SparkContext(conf)
val myArray = Array(1,2,3,4,5)
val myRDD = sc.parallelize(myArray)
myRDD.collect.foreach(println)
}
}
----------------------------------------------------------------------------------------
Right Click on Test.scala -> Run AS -> Scala Application


It's working!!! Have fun with Spark :)
Thank you for patiently reading my blog. Hope you have successfully configured Spark on your Eclipse IDE.
Stay connected for future posts!!
Hi Mohit.. Thank you for the very useful article. It's really easy to follow and very useful.
ReplyDeleteMuralidhar
Thanks mate :)
ReplyDeleteIt worked for me. However, I did not understand the usage of settings.xml. I tried without placing the settings.xml file and still worked. Could you please explain its importance?
ReplyDeleteThank you in in advance.
Muralidhar
Settings.xml is used to configure maven execution. When you install maven separately, then it is required to configure maven. However with eclipse it might not required unless you don't want to change default settings. Like if your server require authentication info or some plugin details, you have to incorporate in settings.xml. It may be incorporated in pom.xml as well, but it is preferred to make it global instead of project specific. Here settings.xml comes into picture. I hope this clear your doubt. For more details you can refer maven documentation. :)
DeleteYes, got it now. Thank you. Is it possible for you to publish a post on Spark-Hbase working model/usecase.
DeleteHi Mohit... Thanks for the article. It is very useful.
ReplyDeleteWelcome 😊
Delete